
你家的 系统为什么一上线就崩?不是服务器不够,是设计从根上就没经得起折腾 别再迷信“多买几台云服务器就能扛住流量”这套话术了。现实是——促销日一到,接口超时、页面白屏、登录失败,用户骂得比
你家的SaaS系统为什么一上线就崩?不是服务器不够,是设计从根上就没经得起折腾
别再迷信“多买几台云服务器就能扛住流量”这套话术了。现实是——促销日一到,接口超时、页面白屏、登录失败,用户骂得比运维睡得还少。半夜爬起来看日志,发现全是红字,心都凉了半截。
真正的问题从来不在硬件,而在于架构从一开始就是个“纸糊的堡垒”。
不是能不能扛,而是怎么死得不难看。
记得有一次双十一大促前,一个号称“百万并发”的系统,压测刚冲到8000并发,数据库连接池直接炸了,主库锁表,订单模块彻底瘫痪。事后复盘,一句话总结:没人想过“连接池最大值设多少才合理”,全靠默认配置硬撑。结果呢?一场活动,毁了一年口碑。
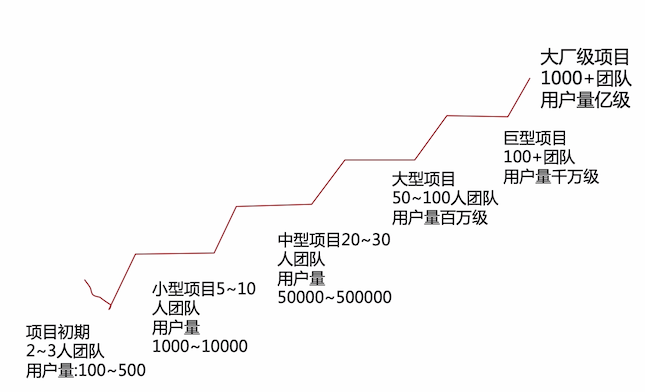
第一步:先搞清楚,“千万级用户”到底意味着什么?别拿理想模型骗自己
每秒至少要处理1000 请求(按日活500万估算)——这还是理论值,真实场景里,峰值可能翻倍甚至三倍。
99.9%可用性听着挺美,一年最多停机52分钟,可只要一次宕机超过10分钟,客户投诉就来了,合同违约风险也跟着来。
响应时间必须控制在500毫秒以内——用户等1.2秒还没反应,点击率直接腰斩。
数据库不能单点挂掉,但万一主库挂了,从库同步延迟可能拖到十几分钟,期间所有写操作全堵住,简直像在等天亮。
✅ 实战建议:压力测试别只跑“理想路径”。
用 Locust k6 模拟真实用户行为:登录→浏览商品→加购→结算→支付→查看订单。
从100并发起步,每10分钟加100,直到系统出现明显卡顿或错误率上升。
重点盯住:哪个接口最先变慢?哪个服务最先报错? 别指望系统像论文里那样线性扩展,那都是理想化模型。
⚠️ 真实提醒:别信“模拟10万用户同时登录”这种说法。
人在实际使用中不会匀速发请求,而是集中在某一时间段爆发。比如吉隆坡午后暴雨天,用户突然集中刷新天气预警页面,瞬间冲高3000并发,系统照样炸。这不是“突发”,这是常态。
第二步:别再堆“大而全”的系统了,分层解耦才是救命稻草
把用户管理、订单、消息、支付、日志全塞在一个应用里?等着被连环崩吧。
每个模块独立部署,用API通信,绝不共用数据库。
微服务框架(Spring Cloud / K8s)是标配,但别为了“时髦”强行拆分。
有些功能本来就不复杂,比如“用户头像上传”,拆成独立服务反而增加调用链路开销,纯属自找麻烦。
️ 防坑指南:
别用同一个数据库表存所有数据。曾经有个项目,用户信息和订单记录混在一个表里,查询慢不说,一改字段结构,十几个服务一起报错,谁也救不了。
跨服务调用必须加熔断机制(Hystrix / Sentinel),否则一个服务雪崩,全网瘫痪,连回滚都来不及。
本地缓存(Caffeine) Redis 双层缓存确实能降延迟,但缓存失效策略必须明确,不然数据不一致问题比性能问题更致命。
行业共识:
大部分中小规模系统,用 Go Gin PostgreSQL Redis 已经够用,没必要上 Java Spring 全栈。
成本低、启动快、维护简单,平替方案根本不需要“微服务”那套复杂流程。
(当然,如果你团队里全是老派Java程序员,那另说……)
第三步:数据库不是万能药,读写分离 缓存也挡不住“手抖”
读写分离怎么做?
写走主库,读走从库,主从同步延迟控制在1秒内——这已经是极限了。
可现实中,主库写入频繁时,从库延迟可能达到3~5秒,尤其在高峰期。
如果业务要求“查到的数据必须实时”,那读写分离这条路根本走不通。
真实案例:某金融类应用,用户查余额时看到的是旧数据,导致一笔误操作转账被拒绝,客户投诉到监管机构。这可不是小问题,是合规红线。
缓存怎么用?
高频数据放Redis,命中率目标85%以上——说起来容易,做起来难。
一旦缓存失效或网络抖动,所有请求直扑数据库,瞬间击穿连接池。
本地缓存(Caffeine)能降低网络延迟,但每个节点缓存独立,数据一致性靠手动刷新,极易出错。
✅ 实操建议:
设置缓存过期时间(10分钟为宜),但关键数据必须设置“主动更新机制”,比如订单状态变更后立刻清除缓存。
用 Redis Cluster 代替单实例,避免单点故障;但集群模式下,键分布不均会导致某些节点负载过高,需监控哈希槽使用情况。
❗劝退指南:
如果你的系统数据量不到1亿条,且读写频率不高,完全没必要上分库分表。
用 ShardingSphere 或 TiDB 的成本(人力、运维、调试)远高于收益,除非你真有几十亿条数据,否则纯属自找麻烦。
第四步:流量入口防炸?CDN 负载均衡只是起点,自动扩缩容才是真功夫
静态资源走CDN,全球加速——没问题,但别指望它解决动态请求问题。
负载均衡器(Nginx / ALB)分发请求,但如果后端服务本身有瓶颈,负载均衡只会让问题更严重。
自动扩缩容是核心,但规则设定必须结合真实业务特征。
关键动作:
在阿里云/腾讯云/AWS上配置弹性伸缩组,但别只看CPU。
如果是短时突发流量,可能触发“无限扩容”;
如果是内存泄漏,哪怕CPU不高,也会撑爆服务。
CPU > 70%持续5分钟 → 扩容?不一定对。
正确做法:同时监控内存、连接数、队列长度,综合判断是否扩容。
⚠️ 致命盲点:
某次活动,系统自动扩了8台实例,但新实例启动后,初始化时间长达3分钟,期间无法接收请求,导致服务短暂不可用。
解决方案:预热机制必须加,比如启动后先跑一次健康检查,确认能响应再加入负载池。
️ 平替方案:
如果预算有限,可以用 Nginx Keepalived 实现简单负载均衡 手动扩缩容,配合脚本定时检测,成本只有云原生的1/5,适合中小型项目。
第五步:监控告警不是摆设,而是防止“半夜救火”的最后一道防线
监控项必须覆盖:服务器状态、接口响应时间、数据库连接数、缓存命中率、错误率。
用 Prometheus Grafana 做可视化面板——前提是能看清异常趋势,而不是只看“绿灯”。
告警规则要具体:比如“错误率超过1%持续1分钟”才通知,否则每天收到几十条告警,根本没人管。
真实教训:
某次系统升级后,短信接口错误率从0.1%升到3%,但因为没设置阈值,直到用户大量投诉才被发现。
后来改成了:“连续5分钟错误率 > 0.5%”立即发群通知,问题平均提前4小时发现。❗隐性代价:
监控系统本身也会出问题,比如指标采集失败、数据丢失。
一旦监控失效,你等于在黑暗里开车,哪怕系统还在跑,也看不见哪里出了事。
✅ 推荐组合:
用 Prometheus Alertmanager 钉钉/企业微信推送,支持分级告警。
每周抽查一条历史告警,确认是否被正确处理——否则就是“形式主义监控”。
为什么说“1000人团队”不是靠人海战术?真相是分工与纪律
人数多不代表能力强,一堆人乱改代码,系统比一个人还难维护。
真正的关键是:每个小组只负责一个模块,职责清晰,流程标准化。
前端、后端、数据库、运维、安全,各司其职,不允许越权操作。
️ 实操细节:
用 DevOps 流水线实现自动部署、自动测试、自动回滚——但别指望一次成功。
每次上线前必须跑全链路压测,发现问题当场记录、当天闭环。
某次发布,因未清理缓存导致用户看到旧价格,线上问题2小时内修复,但已造成损失。
✅ 最重要的一点:所有人必须遵守统一的技术规范文档。
比如“接口返回格式必须包含
code、msg、data字段”,否则下游无法解析。有人想“我随便写个
status=ok就行”?不行,必须强制校验。❗劝退指南:
如果你是小团队(<10人),别追求“千人团队”的架构。
不需要复杂的微服务、不用搞K8s编排、也不用建专门的DevOps岗。
用 单一应用 本地缓存 云数据库 定时任务 就够用了。
把精力放在产品逻辑和用户体验上,而不是“看起来很高级”的技术堆砌。
常见问题(FAQ)
Q1:我只有10个人,能做千万级系统吗?
可以,但前提是架构设计必须提前规划好。
人数不影响系统能力,关键是能不能把系统拆得清、管得住。
如果你连“服务边界”都分不清,再多的人也只是在重复造轮子。
(别说10个人,100个人也一样,架构不对,全是浪费)
Q2:要不要用云原生?是不是贵?
必须用容器 编排,但不一定要上K8s。
初期可选 Docker 轻量级调度工具(如Nomad),后期再迁移到K8s。
贵的不是技术,是“不懂装懂”带来的反复重构和运维事故。
(见过太多团队花半年时间学K8s,最后发现根本用不上,回头还得重来)
Q3:数据库会不会成为瓶颈?
会,但不是唯一瓶颈。
读写分离 缓存 分库分表是常规手段,但必须配合合理的索引设计和慢查询分析。
没有优化过的查询,再牛的架构也扛不住。
(别以为加个索引就能万事大吉,慢查询日志才是真正的照妖镜)
Q4:怎么保证系统不出错?
靠自动化测试 全链路压测 实时监控。
人工试不了,错了也发现不了。
每次上线前必须跑一遍完整流程测试,否则就是赌命。
(我见过最离谱的一次,上线前没人跑压测,结果用户一刷,系统直接崩了,第二天老板开会问:“你们怎么没发现?”——答:“我们以为能扛。”)
Q5:需要多少服务器?
没有固定数量。
取决于业务复杂度。
一般初期用10台左右虚拟机起步,配合负载均衡和自动扩缩容,能支撑百万级用户;
再往上就要考虑分布式架构。
但别盲目扩大规模,先看清楚:是流量真的来了,还是你自己的系统太脆弱?
(很多团队不是被用户吓倒,是被自己吓倒的)